
ダミー変数化後、訓練データ・テストデータで列数が違う場合
最近機械学習の勉強を進めているのだが、ちょっと詰まった箇所があったので備忘録として記事に書いておくことにした。
カテゴリ変数を数値化するために、get_dummies関数を使ってダミー変数化する手法はデータ分析や機械学習でよく使われる。
しかし、訓練用のデータとテスト用のデータでダミー変数にした要素の数が違い、そのまま食わせるとエラーが出てしまうことがある。
例えば以下のような適当なサンプルデータがあったとする。
import pandas as pd
import numpy as np
train = pd.DataFrame({
'月' : [1, 2, 3, 4, 5],
'日' : [1, 5, 10, 20, 30],
'名前' : ['伊藤', '近藤', '清水', '堀', '中島']
})
test = pd.DataFrame({
'月' : [6, 8, 10],
'日' : [12, 16, 20],
'名前' : ['伊藤', '伊藤', '近藤']
})train
test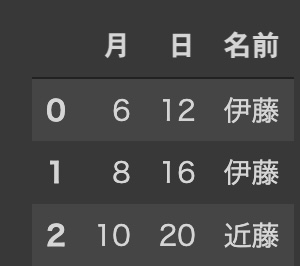
これらのデータをpd.get_dummies関数でダミー変数化するとこうなる。
train_d = pd.get_dummies(train)
train_d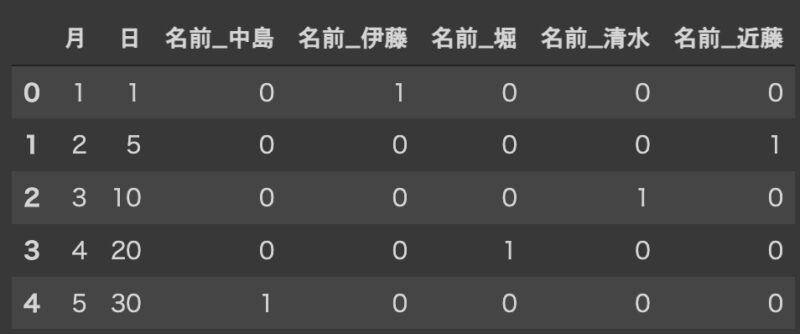
test_d = pd.get_dummies(test)
test_d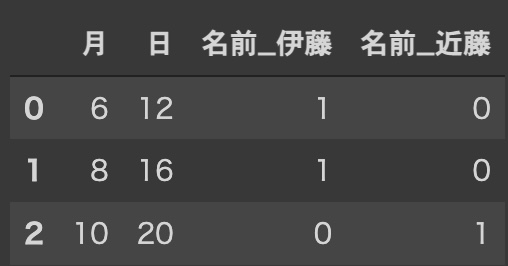
このように訓練データでは5つの要素(ここでは名前)があるが、テストデータには2つの要素しかない。
つまりダミー変数の数、列数が違うためこのままではエラーが出てしまうのだ。
pd.Categorical()で対処
これに対処するには関数pd.Categorical()を使う。
まず、訓練用のデータからunique()で重複のないユニークな要素を抽出。
name = train['名前'].unique()
name
次に上の要素一覧をpd.Categorical()を使ってテストデータの同列にも適用する。
第一引数に適用したい列、第二引数に要素の一覧を格納した変数を指定する。
test['名前'] = pd.Categorical(test['名前'], name)
test['名前']
するとテストデータの当該列要素は2つしかないものの、下の「Categories」の部分を見れば訓練データにしかない他3つの要素も適用されているのが分かるだろうか。
その上でget_dummies関数を適用。
test_data = pd.get_dummies(test)
test_data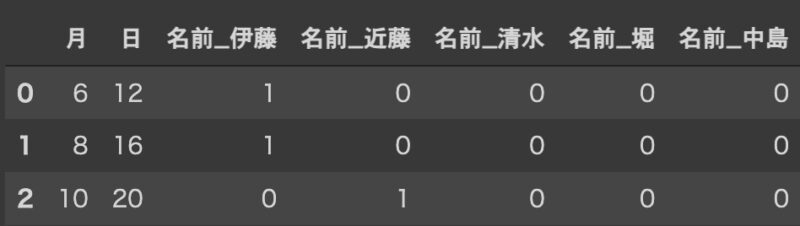
このようにテスト用のデータには含まれない要素もダミー変数の列として表示されるようになった。
なお、ここもちょっと詰まった所なのだが、上記の訓練データの要素を使った一覧は、元の訓練データにもpd.Categorical関数によって適用しないと、列数は同じでもダミー変数の順番が違ってしまう場合もある。
そのため元の訓練データにもpd.Categorical()を適用する。
train['名前'] = pd.Categorical(train['名前'], name)
train_data = pd.get_dummies(train)
train_data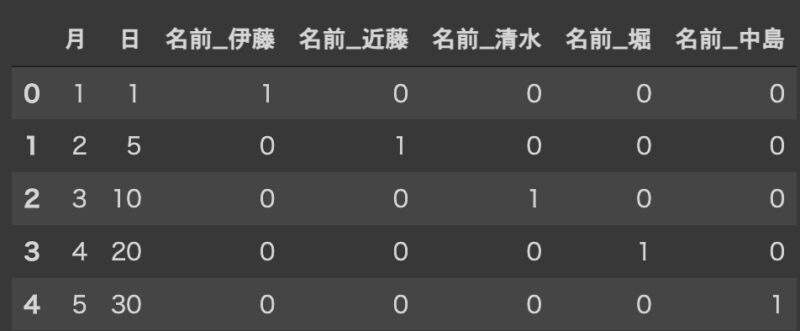
これで訓練用データとテスト用データでダミー変数の列数、順番が揃い、機械学習に使うことができるようになった。


コメント